https://learn.microsoft.com/en-us/dotnet/api/system.collections.generic.list-1.sort?view=net-7.0
List<T>.Sort Method (System.Collections.Generic)
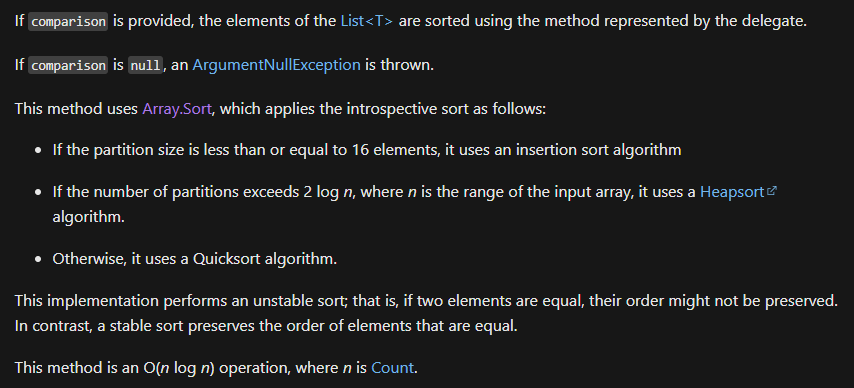
Sorts the elements or a portion of the elements in the List<T> using either the specified or default IComparer<T> implementation or a provided Comparison<T> delegate to compare list elements.
learn.microsoft.com
Unity로 개발할 때, Sort를 흔하게 사용하게 된다. 유니티 Sort는 어떤 정렬 알고리즘을 사용하고 있을까?
Unity의 기본 정렬 알고리즘: 인트로소트(Introsort)
Unity는 .NET 프레임워크를 기반으로 동작하며, 컬렉션의 정렬을 위해 .Sort() 메소드를 제공한다. 이 메소드는 내부적으로 인트로스펙티브 정렬(Introspective Sort), 줄여서 인트로소트(Introsort) 알고리즘을 사용한다. 인트로소트는 퀵정렬, 힙정렬, 삽입정렬을 결합한 하이브리드 알고리즘이다. (https://ko.wikipedia.org/wiki/%EC%9D%B8%ED%8A%B8%EB%A1%9C_%EC%A0%95%EB%A0%AC)
퀵정렬의 효율성과 한계
퀵정렬은 분할 정복 방식을 사용하는 알고리즘으로, 평균적으로 O(n log n)의 시간 복잡도를 가진다. 데이터 요소들을 피벗을 기준으로 분할하여 정렬하는 방식인데, 피벗 선택이 좋을 경우 매우 효율적이다. 특히 랜덤한 데이터나 일반적인 분포를 가진 데이터에서는 빠른 성능을 보인다. 그러나 피벗 선택이 부적절하여 분할이 균등하지 않게 이루어지면, 최악의 경우 O(n²)의 시간 복잡도가 발생한다. 이는 이미 정렬된 배열이나 모든 요소가 동일한 케이스 등에 발생할 수 있다.
힙정렬로의 전환
인트로소트는 퀵정렬의 이러한 최악의 성능을 보완하기 위해 설계되었다. 재귀 호출의 깊이가 일정 수준을 넘어가면 자동으로 힙정렬로 전환한다. 힙정렬은 항상 O(n log n)의 시간 복잡도를 보장하는 알고리즘으로, 최악의 경우에도 안정적인 성능을 제공한다. 힙정렬은 퀵정렬에 비해 평균 성능은 다소 떨어질 수 있지만, 최악의 상황을 방지하기 위한 안전장치로 사용된다.
작은 컬렉션에 대한 삽입정렬
데이터의 양이 적을 때는 삽입정렬이 다른 정렬 알고리즘보다 더 빠르게 동작할 수 있다. 그 이유는 다음과 같다:
- 알고리즘의 단순성: 삽입정렬은 매우 단순한 방법으로 작동한다. 리스트의 각 요소를 앞에서부터 하나씩 확인하며, 적절한 위치에 삽입해 나가는 방식이다. 복잡한 연산이나 구조를 필요로 하지 않는다.
- 메모리 접근의 효율성: 데이터가 메모리에 연속적으로 저장되어 있어, 컴퓨터가 데이터를 읽고 쓰는 속도가 빠르다. 이는 작은 데이터셋에서 특히 유리하게 작용한다.
- 오버헤드의 최소화: 작은 배열에서는 함수 호출이나 재귀로 인한 오버헤드가 전체 성능에 큰 영향을 줄 수 있다. 예를 들어, 퀵정렬이나 힙정렬은 재귀 호출을 많이 사용하므로 작은 데이터셋에서는 오히려 느려질 수 있다. 반면에 삽입정렬은 이러한 추가 작업이 없기 때문에 빠르게 처리할 수 있다.
인트로소트는 이러한 장점을 활용하여, 정렬해야 할 부분 배열의 크기가 작을 경우 삽입정렬을 적용한다. 일반적으로 요소의 개수가 16개 이하인 작은 배열에 대해서는 삽입정렬을 사용한다. 이렇게 하면 작은 데이터셋에서는 삽입정렬의 빠른 성능을, 큰 데이터셋에서는 퀵정렬과 힙정렬의 효율성을 모두 얻을 수 있다.
쉽게 말해서:
- 작은 데이터셋에서는 삽입정렬이 더 빠르다.
- 복잡한 알고리즘은 작은 데이터셋에서 오히려 시간이 더 걸릴 수 있다.
- 인트로소트는 이 두 가지를 모두 활용하여 최적의 성능을 낸다.
예를 들어,
책상 위에 몇 개의 책만 정렬할 때는 복잡한 방법이 필요 없이 한 권씩 위치를 맞춰가며 정렬하는 것이 빠르다. 하지만 책의 양이 많아지면 더 효율적인 정렬 방법이 필요해진다. 인트로소트는 이런 상황에 맞게 작은 경우에는 간단한 방법을, 큰 경우에는 복잡하지만 효율적인 방법을 사용하도록 설계된 알고리즘이다.
이처럼 유니티 Sort는 매우 효율적인 알고리즘으로 구성되어있기 때문에, 대부분의 상황에서는 따로 정렬 알고리즘을 구현할 필요는 없을 것이다.
'공부 > 개념 & 유용한 내용' 카테고리의 다른 글
| XZ 평면에서 특정 방향을 바라보도록 회전 (0) | 2023.08.23 |
|---|---|
| 유니티 게임 클라이언트 프로그래머 로드맵 (1) | 2023.06.15 |
| 에디터 코루틴 (0) | 2023.03.30 |
| Caching (캐싱) 이란? (0) | 2020.09.25 |
| 코루틴 최적화 (가비지 덜 생성되게) (1) | 2020.09.24 |